Paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models Repository: deepseek-ai/Engram Released: January 2026
Traditional LLMs waste computational resources by using neural networks to “re-derive” static factual knowledge on every inference. This creates:
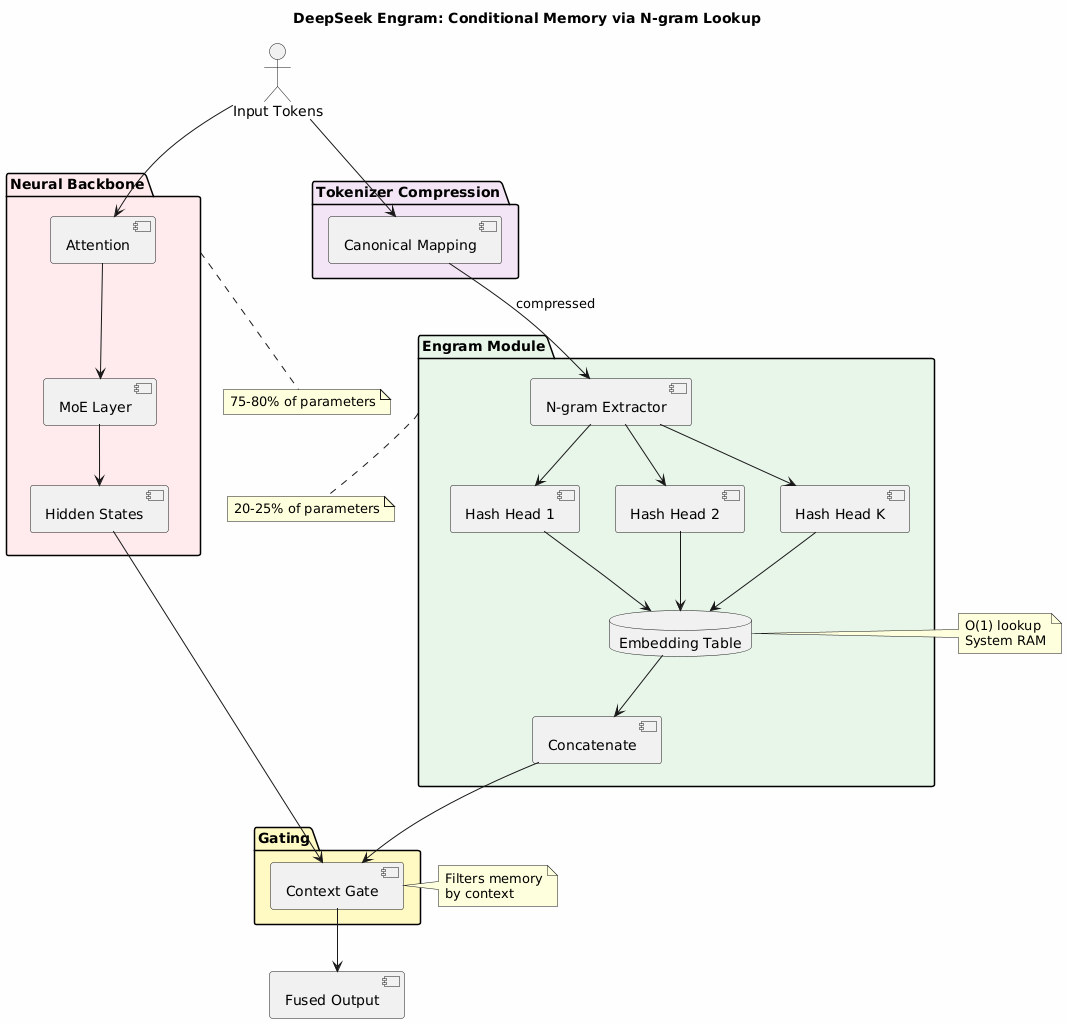
Engram introduces conditional memory as a complementary axis to neural computation:
| Approach | Purpose | Complexity | Storage |
|---|---|---|---|
| Neural (MoE) | Dynamic reasoning | O(n) | HBM/GPU |
| Engram | Static knowledge lookup | O(1) | System RAM |
Compresses equivalent tokens to canonical forms:
Apple, apple, APPLE → appleExtracts sliding windows of tokens (n-grams) from input sequence for hash-based lookup.
Uses K distinct hash heads per n-gram order to reduce collisions:
memory_vector = concat(
hash_head_1(ngram) → embedding_1,
hash_head_2(ngram) → embedding_2,
...
hash_head_K(ngram) → embedding_K
)
The gating mechanism uses context from attention layers to filter retrieved memories:
This prevents hallucination from irrelevant or conflicting memorized facts.
DeepSeek discovered a U-shaped scaling law for allocating parameters:
| Allocation | Performance |
|---|---|
| 100% Neural | Baseline |
| 75-80% Neural + 20-25% Engram | Optimal |
| 60% Neural + 40% Engram | Suboptimal |
“Reallocating roughly 20%–25% of the sparse parameter budget to Engram yields the best performance.”
| Benchmark Type | MoE Baseline | Engram-27B | Improvement |
|---|---|---|---|
| Complex Reasoning | 70% | 74% | +4% |
| Knowledge Tests | 57% | 61% | +4% |
| Code Generation | Baseline | Improved | Consistent |
| Mathematics | Baseline | Improved | Consistent |
Tested on: Big-Bench Hard, ARC-Challenge, MMLU
| Resource | Traditional LLM | Engram LLM |
|---|---|---|
| HBM Usage | High (all params) | Reduced (compute only) |
| System RAM | Minimal | Used for Engram tables |
| GPU Compute | All operations | Reasoning only |
This decouples memory scaling from expensive HBM, enabling larger knowledge bases at lower cost.
# From DeepSeek's demo repository
pip install torch numpy transformers sympy
python engram_demo_v1.py
| Pattern | Relationship |
|---|---|
| Agentic RAG | Alternative knowledge retrieval approach |
| MoE Architecture | Neural backbone that Engram augments |