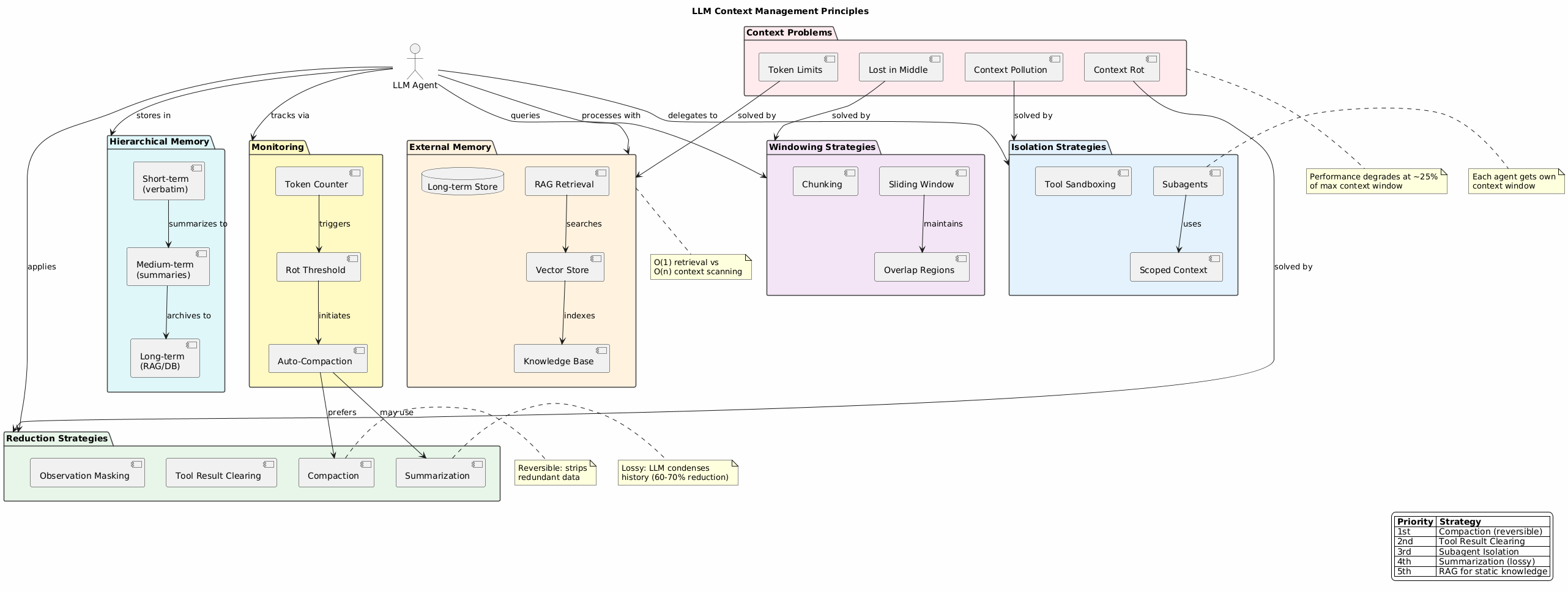
A comprehensive index of techniques to prevent context pollution and optimize LLM agent performance.
LLMs suffer from several context-related issues:
| Problem | Description | Impact |
|---|---|---|
| Context Rot | Performance degrades as context grows | Quality drops at ~25% of max window |
| Lost in Middle | Information in middle of context is poorly recalled | Beginning/end bias |
| Context Pollution | Irrelevant data crowds out useful information | Degraded reasoning |
| Token Limits | Hard cap on context window size | Truncation, errors |
Prevent pollution by separating concerns:
Each subagent gets its own clean context window:
Lead Agent (high-level plan)
├── Research Agent (isolated 100k context)
├── Code Agent (isolated 100k context)
└── Review Agent (isolated 100k context)
Benefits:
Tool outputs don’t pollute main conversation:
Each model call sees minimum required context:
Shrink context while preserving information:
Reversible - strips redundant data that exists elsewhere:
Before: [full file contents in context]
After: [reference to file path - can re-read if needed]
LLM condenses history when compaction isn’t enough:
Priority Order:
Remove raw tool outputs deep in history:
Target environment observations only:
Move knowledge outside the context window:
| Component | Purpose |
|---|---|
| Vector Store | Semantic similarity search |
| Knowledge Base | Structured fact storage |
| Long-term Store | Persistent memory across sessions |
When to use RAG vs Context:
Process long content in manageable chunks:
[Window 1: tokens 0-4000 ]
[Window 2: tokens 3000-7000 ]
[Window 3: tokens 6000-10000 ]
Maintain coherence across windows:
Break content at semantic boundaries:
Multi-tier storage with different characteristics:
| Tier | Content | Retention |
|---|---|---|
| Short-term | Verbatim recent turns | 8-10 exchanges |
| Medium-term | Compressed summaries | Session duration |
| Long-term | RAG/database | Persistent |
Implementation:
Query → Check short-term → Check medium-term → RAG long-term
↓ ↓ ↓
Full detail Summary context Retrieved facts
Proactive context management:
Track usage before hitting limits:
if token_count > (max_context * 0.75):
trigger_compaction()
Don’t wait for API errors:
Automatic context management:
Sliding Window (recent 8-10 messages)
+ RAG (knowledge base)
+ Periodic summarization (>20 exchanges)
Subagents (isolated contexts)
+ Tool result clearing
+ File reference compaction
+ External memory for docs
Hierarchical memory
+ RAG for sources
+ Summarization for synthesis
+ Scoped context per subtask
| Anti-Pattern | Problem | Solution |
|---|---|---|
| Stuffing entire codebase | Exceeds limits, rot | Use RAG + file references |
| No summarization strategy | Quality degrades | Implement thresholds |
| Single monolithic context | Pollution spreads | Use subagents |
| Ignoring token count | Sudden failures | Monitor proactively |
| Pattern | Relationship |
|---|---|
| LLM Tool Call | Tool outputs need clearing |
| Agent Orchestration | Subagent isolation |
| Agentic RAG | External memory retrieval |
| Skills Pattern | Scoped context per skill |